Programming
Project Invasives is a proof of concept I built on top of Big Query (a data warehouse on google cloud), designed to integrate citizen science surveys with historic data. This website has a survey application whose data integrates to the standards of the Global Biodiversity Information Facility (GBIF). The purpose of the application is to allow citizen science volunteers to engage with the master data and fill in gaps of where invasive species are present in the San Francisco Bay Area.
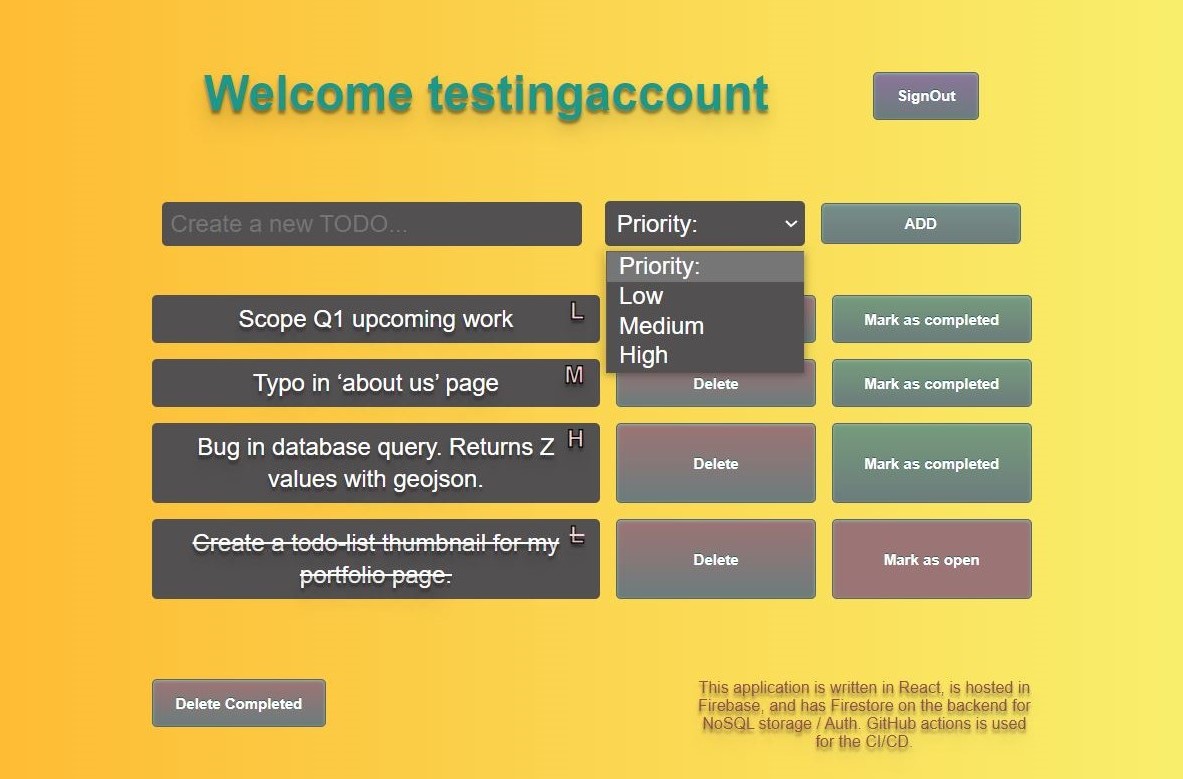
On this page the public has the option to view the project dashboard of invasive species, submit their own invasive species, to browse summary statistics of project progress, or to donate to support the project.
The most interesting part of this system architecture are the pipelines coming into Big Query. Monthly I hit the GBIF database (which contains around 2.3 billion species observations) for all species observations within the general SF Bay Area (approximately 39 million records) and bring this complete dataset into Big Query (all species in the SF Bay Area). But this is too much data to query against and be cost/time efficient, so I subset this dataset down to only invasive species using a California Invasive Species Advisory Committee (CISAC) standardized lookup table of local invasive species. From here I have the dataset down to under a million records. Then I use pipelines in App Engine (daily) to hit my database of volunteer submitted data, join them together, calculate summary statistics (and send them as a JSON to Cloud Storage to be read by the webpage) and display the complete data in Looker Studio. Why use App Engine instead of Cloud Functions? Because App Engine has a longer run time, access to TEMP/system-files, and more CPU/RAM configurations. App Engine now has CRON, so scheduling functions is just as easy as Cloud Functions. In this situation this App Engine instance can only be invoked by CRON and has no public endpoint.